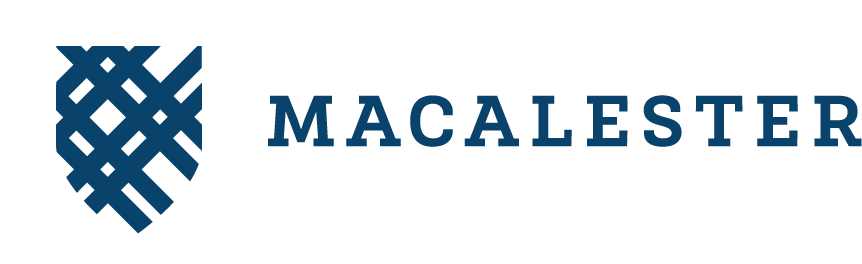| name | sex | total |
|---|---|---|
| Courtney | F | 257289 |
| Courtney | M | 22619 |
| Riley | F | 100881 |
| Riley | M | 92789 |
Reshaping Data
James Normington
Due this Week
- At least 1 Tidy Tuesday by next Friday!
Learning Goals
- Understand the difference between wide and long data format and distinguish the case (unit of observation) for a given data set
- Develop comfort in using
pivot_widerandpivot_longerin thetidyrpackage
Template File
Download a template .Rmd of this activity. Put the file in a Day_08 folder within your COMP_STAT_112 folder.
- This .Rmd only contains examples and 3 exercises that we’ll work on in class.
Describe to your Neighbor
Everyone: Look at this small data set.
Partner A: Describe the structure of the data set in words.
Describe to your Neighbor
Partner A: Close your eyes.
Partner B: Describe the how the structure of the data set changed. Think of describing “steps” taken.
Partner A: Sketch what you think the new data set looks like.
| name | F | M |
|---|---|---|
| Courtney | 257289 | 22619 |
| Riley | 100881 | 92789 |
Describe to your Neighbor
Partner B: Close your eyes.
Partner A: Describe the how the structure of the data set changed. Think of describing “steps” taken.
Partner B: Sketch what you think the new data set looks like.
| name | F | M | ratio |
|---|---|---|---|
| Courtney | 257289 | 22619 | 0.0879128 |
| Riley | 100881 | 92789 | 0.9197867 |
| name | ratio | sex | total |
|---|---|---|---|
| Courtney | 0.0879128 | F | 257289 |
| Courtney | 0.0879128 | M | 22619 |
| Riley | 0.9197867 | F | 100881 |
| Riley | 0.9197867 | M | 92789 |
Wider V. Longer Format
If we want to maintain all of the values in the data set (not collapsing rows with summarize) but have a different unit of observation (or case), we can:
- Make the data wider by spreading out the values across new variables (e.g. total counts for binary “Male” and “Female” names)
- Make the data longer by combining values from different variables into 1 variable (take counts for binary “Male” and “Female” names and combine into one total column)
R Functions
pivot_wider()
- Inputs: data, names_from = var_name, values_from = var_name
pivot_longer()
- Inputs: data, cols = c(
var_name2,var_name2), names_to = “string”, values_to = “string”
R Functions

In Class
Go through the example code in the Rmd file to make sure you understand how we reshape data to be wider and longer.
After Class
- TT4
- Assignment 5 due Wed. 2/22 @ 11:59pm
Part 1 in Chap 7 (Six Main Verbs)
Part 2 in Chap 8 (Reshaping Data)